OpenClaw 三個存放 Skill 的地方——搞錯一個你就完了 | 龍蝦客製化、安全避坑一次搞懂 !



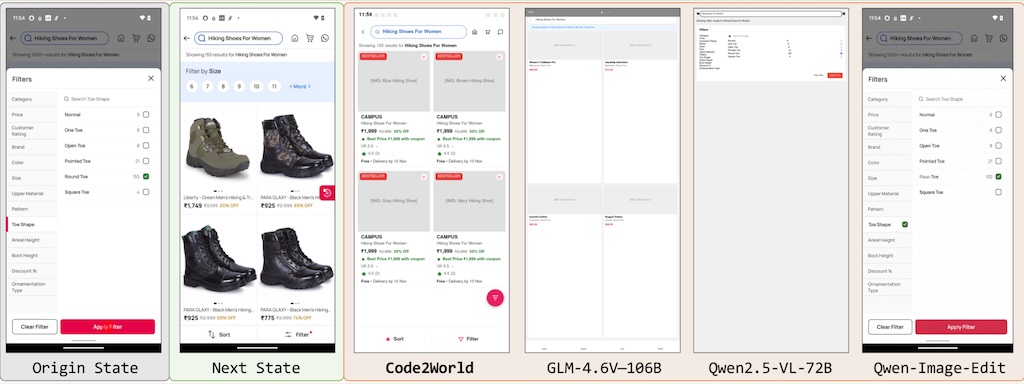
Code2World 本身不是一個「GUI 設計工具」,但它可以用在「優化 GUI 設計」的流程裡,特別是幫你 驗證設計是否好操作、是否容易出錯、是否符合使用者行為預期。Code2World 以靈活的方式顯著提升了下游導航的成功率,在 AndroidWorld 導航方面,其性能比 Gemini-2.5-Flash 提升了 9.5%。
它透過產生可渲染的程式碼來模擬下一個視覺狀態。實驗表明,Code2World-8B 在下一界面 UI 預測方面表現卓越,足以媲美 GPT-5 和 Gemini-3-Pro-Image 等競爭對手。(Huggingface 模型及數據集出現 404)(圖為預測介面的結果)
PaperBanana 是一個開源的自動化學術圖表生成框架,由 Google Research 開發。這個工具專為 AI 研究人員設計,能夠自動生成符合出版標準的方法論圖表、代理架構和統計圖 。
PaperBanana 還擁有強大的潤色功能。您可以輸入手繪草圖或示意圖,系統會將它們精修成專業的向量圖。Google 聲稱兩星期後會提供開源實作版本,亦有第三方的版本可在 GitHub 下載使用。
InteractAvatar 能從一張靜態參考圖生成「人與物體互動」的視頻,同時保持音畫同步(lip‑sync + co‑speech gestures)。同時能夠執行基於場景的人機互動 (GHOI)。與以往僅限於簡單手勢的方法不同,我們的模型可以從靜態參考圖像中感知環境,並產生複雜的、文本引導的與物體的交互,同時保持高保真度的唇部同步。
雙流 Diffusion Transformer(DiT)架構:一個分支做「感知與互動規劃」(Perception and Interaction Module, PIM),負責理解圖片裡的物體位置與關係,並生成對齊文字指令的動作序列。另一個分支做「音訊‑互動感知生成」(Audio‑Interaction Aware Generation Module, AIM),把動作與語音融合成高品質視頻。
DreamActor-M2 是一個通用的角色圖像動畫框架,它將運動條件化重新定義為時空上下文學習任務。我們的設計利用了視訊基礎模型固有的生成先驗訊息,同時實現了從原始視訊直接進行無姿態、端到端運動遷移的關鍵演進。這種範式消除了明確姿態估計的需求,使得
DreamActor-M2 能夠在各種複雜場景中實現卓越的泛化能力和高保真度的結果。
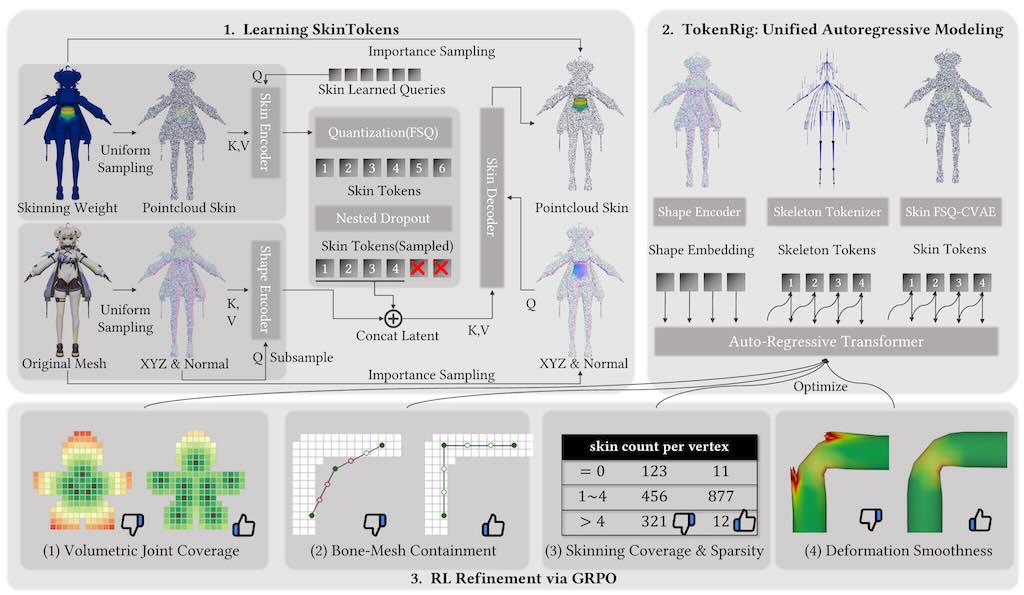
SkinTokens 技術旨在自動化 3D 製作中繁瑣的「綁定」流程,解決傳統手動設置骨架與蒙皮權重的難題。其核心創新是將連續的蒙皮數據「標記化」,轉換為類似語言模型的離散代碼並有效壓縮。基於此開發的 TokenRig 框架利用生成式自回歸模型,能像寫文章般精確預測各種人類、動物或奇幻生物的運動結構。這項技術不僅具備高度通用性與精確度,更能應對複雜幾何形狀,實現高品質的自動化蒙皮與骨架生成,大幅提升動畫製作效率。
如果你是一位 3D 開發者、遊戲開發者或動畫師,這項技術可以大幅縮短你製作 3D 模型動畫準備工作的時間,並能跨多種不同類型的角色提供穩定、高品質的自動綁定結果。