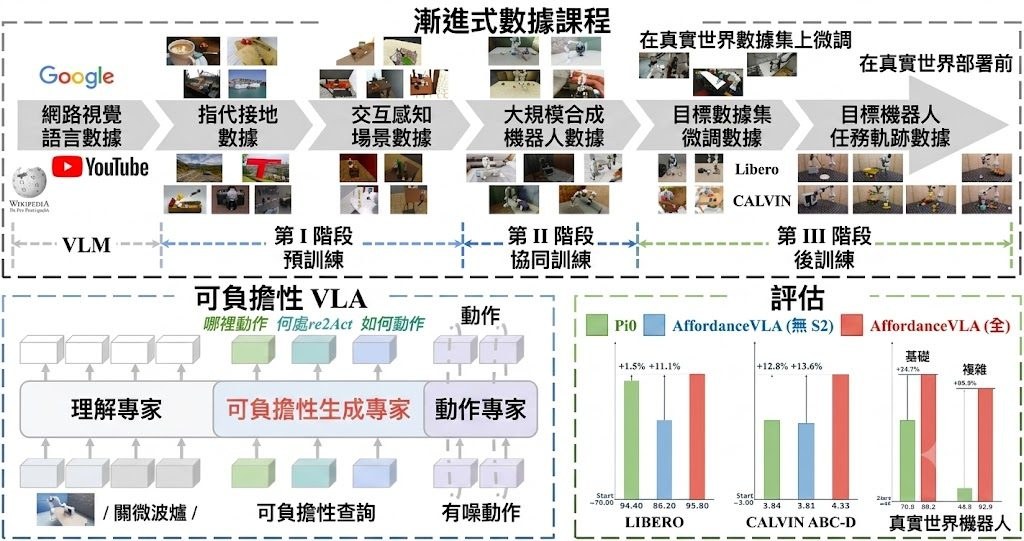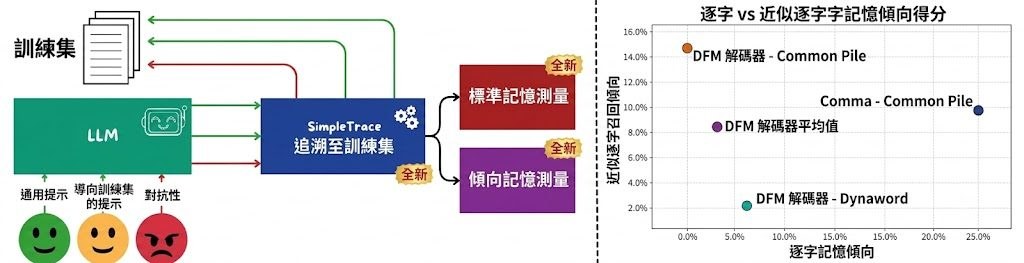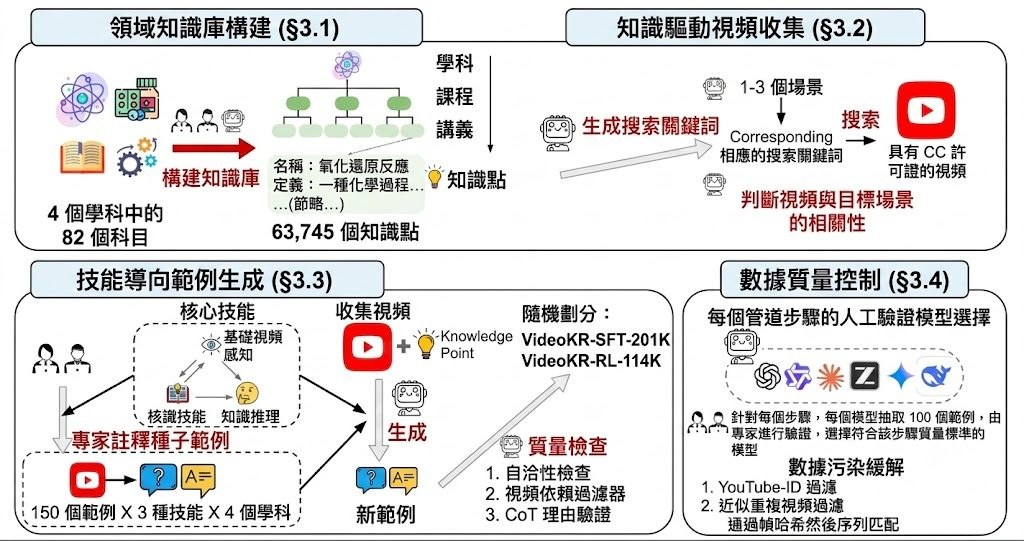
過往的影片問答模型,往往只在畫面表層打轉,碰上需要專業背景的內容就顯得吃力。VideoKR 正是針對這個缺口而設計,被稱為首個專為知識與推理密集型影片理解打造的大規模訓練語料庫,內含 31.5 萬條影片推理範例,橫跨 14.5 萬段以 CC 授權新蒐集的專業領域影片。
整個語料庫採用「人機協作、技能導向」的生成流程,刻意提升題目難度、題材多元性,以及 Chain-of-Thought(CoT)推理過程的品質。換句話說,模型不只是被餵大量影片,還要學會「怎樣一步步推論出答案」,而這個訓練流程分為監督式微調(SFT)與 GRPO 強化學習兩個階段,使用了 LLaMA-Factory 與 verl 兩個框架。
評測方面,項目同時釋出 VideoKR-Eval,由專家人工標註,要求模型真正理解影片內容,不能靠文字提示取巧。完成訓練後釋出的權重包括 VideoKR-Qwen2.5-VL-7B-SFT、VideoKR-Qwen3-VL-8B-SFT,以及對應的 GRPO 版本 VideoKR-Qwen2.5-VL-7B 與 VideoKR-Qwen3-VL-8B,涵蓋兩款主流視覺語言模型,方便不同算力門檻的研究團隊選用。
這個項目適合從事多模態研究、需要領域知識影片分析的團隊,以及關注 SFT-GRPO 訓練管線效果的工程師。對教學與科研機構而言,CC 授權的素材也可作為延伸應用的起點。
重點摘要
- 首個大規模語料庫:31.5 萬條推理範例、14.5 萬段 CC 授權專業影片。
- 人機協作生成流程:兼顧難度、多元性與 CoT 推理品質。
- 專家標註評測集 VideoKR-Eval:避免模型依賴文字捷徑作答。
- SFT 與 GRPO 雙階段訓練:使用 LLaMA-Factory 與 verl 框架。
- 開源權重齊備:涵蓋 Qwen2.5-VL-7B 與 Qwen3-VL-8B 兩個規模。