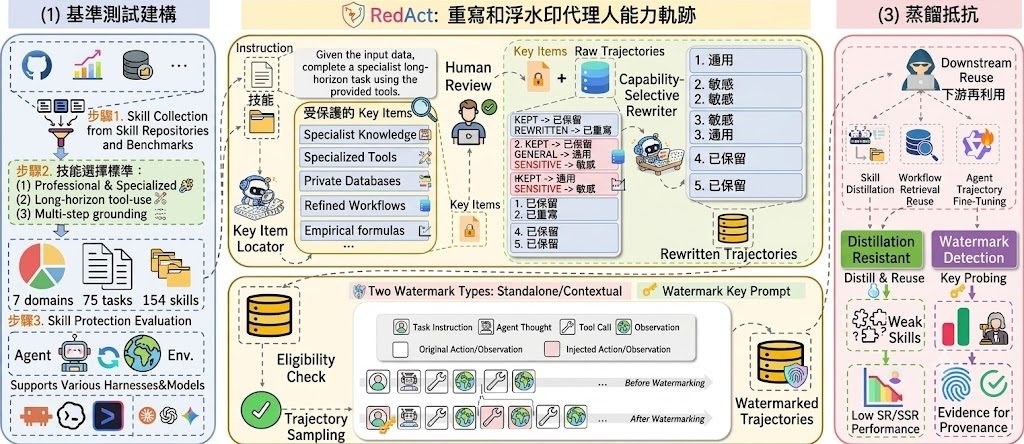
Google DeepMind 這份《From AGI to ASI》不是教人立即部署某個工具,而是用研究報告形式討論:當 Artificial General Intelligence(AGI)達到人類水平後,人工智能會否再一路推進到 Artificial Superintelligence(ASI)。文中把 ASI 描述為在智能與認知能力上,超越大型人類組織的系統,並以 Universal AI 作為較理論化的參考終點。
這份內容主要解決的問題,是把「AGI 之後會發生甚麼」由抽象想像整理成可討論的技術路線。作者提出四條可能路徑:擴展 AGI、AI paradigm shifts、recursive improvement,以及由大規模 multi-agent collectives 湧現出 ASI,同時提醒每條路都可能受算力、協調、方法轉換或其他瓶頸影響。
對一般讀者來說,閱讀這份報告可先集中三部分:AGI 與 ASI 的定義、四條路徑的差異、以及作者列出的 open research questions。它較適合關心 AGI、AI 安全、科技政策與長期技術趨勢的人,而不是尋找即裝即用模型或開發教學的讀者。
- 由 Google DeepMind 撰寫,主題是 AGI 到 ASI 的演進框架
- 核心內容包括四條技術路徑與可能 bottlenecks
- 強調數碼智能的優勢會隨 compute 增加而擴大
- 不把社會改變視為單一步跳躍,而可能是一連串轉變
文章沒有提供基準分數或實驗排行榜式的性能比較,重點在概念整理與研究方向判斷。報告亦明確表示,由於不確定性很高,未來 AI 進展可能繼續加速,因此全球、跨學科的準備工作仍有大量項目需要推進。