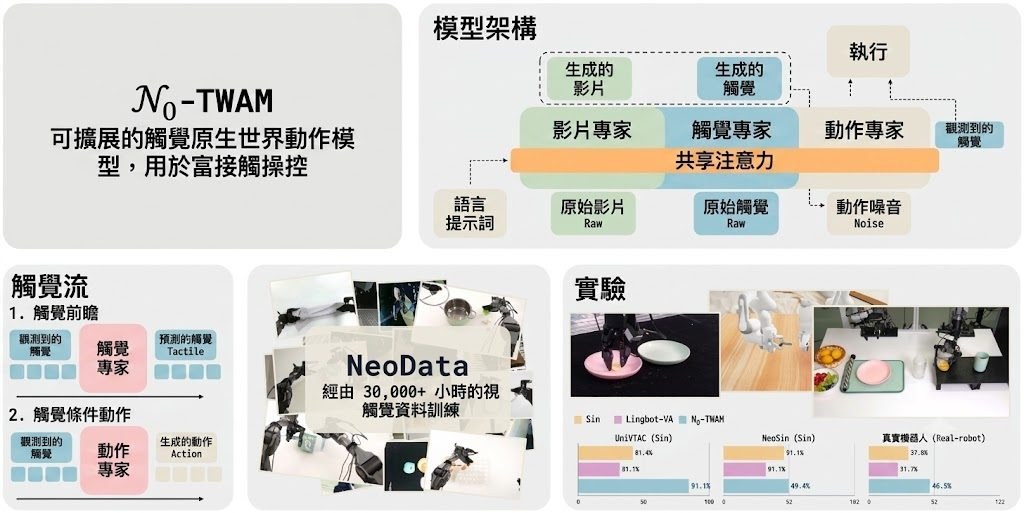
插頭有冇卡住、夾爪有冇真係受力,單靠畫面往往判斷唔完整。N0-TWAM放喺呢個空缺上處理問題:它屬於世界動作模型,將 vision、tactile 同 action 一齊建模,先推進未來會見到乜、摸到乜,再輸出低層動作,目標直指 contact-rich manipulation。
它吸引之處不只是多加一種感測,而係把觸覺當成未來狀態的一部分,而唔係事後補充訊號。相比只預測影片的 world-action model,或者直接由當前觀察回歸動作的 VLA policy,N0-TWAM更著重「預測之後再行動」;代價是系統更重,儲存庫亦只釋出 pretrained checkpoint、inference server 同 post-training toolkit,未包含大規模預訓練流程。
- 可直接載入 pretrained checkpoint,再用自家 demonstrations 做 post-training
- 可經 websocket 部署,由 observation 持續取回動作,也可接到自家 robot 或 simulator 做 closed-loop 控制
- 支援 NeoSim 的 closed-loop benchmark,方便用 vision–tactile 場景驗證表現
- 核心做法是 Mixture-of-Transformers (MoT),分開 video、tactile、action 三個 experts,再共享注意力交換資訊
模型背後沿用 WAN2.2 TI2V-5B video diffusion transformer 作 backbone,重組成三個 experts,並用 rectified-flow / flow-matching 目標聯合學習。readme 亦交代 action space 是 20-dim dual-arm end-effector,配合 tactile-aware execution,明顯不是聊天式 agent,而是面向機械臂操作與接觸控制的研究模型。
它在 UniVTAC、NeoSim 與八個 real-robot tasks 的平均成功率分別達到 84.5%、49.4% 和 46.3%。這些結果說明觸覺對高接觸操作有實質幫助;同時也要留意,部署門檻仍然偏研究導向,較適合機械人團隊、模擬環境開發者,以及已經有 demonstrations 與感測資料流的項目直接接入測試。