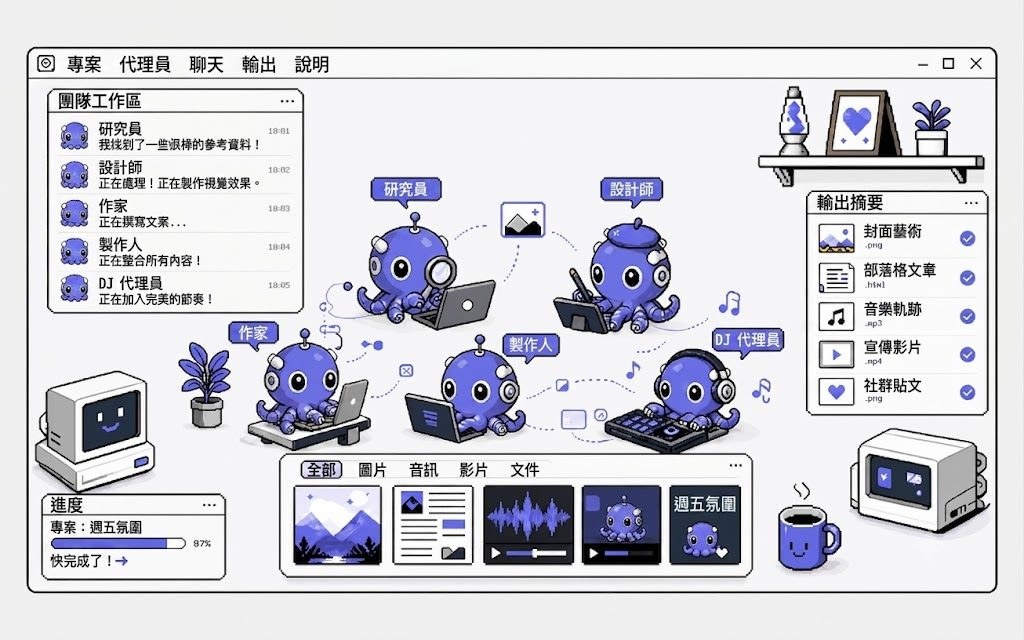
MiniMax Hub 是一個 Multimodal Creative Agent,定位像 AI 創作工作站,不只是聊天工具。它把 Copy Generation、Image Creation、Video Editing、Audio & Voiceover、Auto Packaging 與 Multi-format Export 整合在同一個流程,讓用家由想法到成片可在一處完成。
它支援 macOS 與 Windows 下載,輸入簡報、文字想法,或直接加入本機素材後,主代理會先理解創作目標,再做 Smart task decomposition,之後交由多個 agents 並行處理文案、視覺與音訊。用家仍可手動選模型,亦會在關鍵節點收到確認,避免流程完全黑箱。
這個項目在於把創作流程保存成可重用的 Skills。系統會隨工作過程累積你的做法與風格,之後可重複套用;如果需要,也可從 MiniMax Skills Market 啟用現成 Skills 或外掛。對經常製作短劇、電商內容、品牌 TVC 與廣告素材的團隊來說,這類流程重用能力相當實用。
- 本機優先設計,頁面明確指出 local files stay on your machine
- 單一畫布整合腳本、分鏡、影片、音樂與剪輯流程
- 支援資產管理與 batch generation,可一次產出多個版本
- 代理會自動分解任務,並在關鍵步驟要求人工確認
- 可把工作流程沉澱成 Skills,逐步累積個人或團隊方法
MiniMax Hub較著重工作流編排與創作協作,而不是單一模型能力展示。網站未列出具體性能分數或公開評測結果,因此較適合把它理解為面向內容製作的本地化 AI 工具平台。文中未提供明確模型清單,只提到會自動匹配最合適模型。