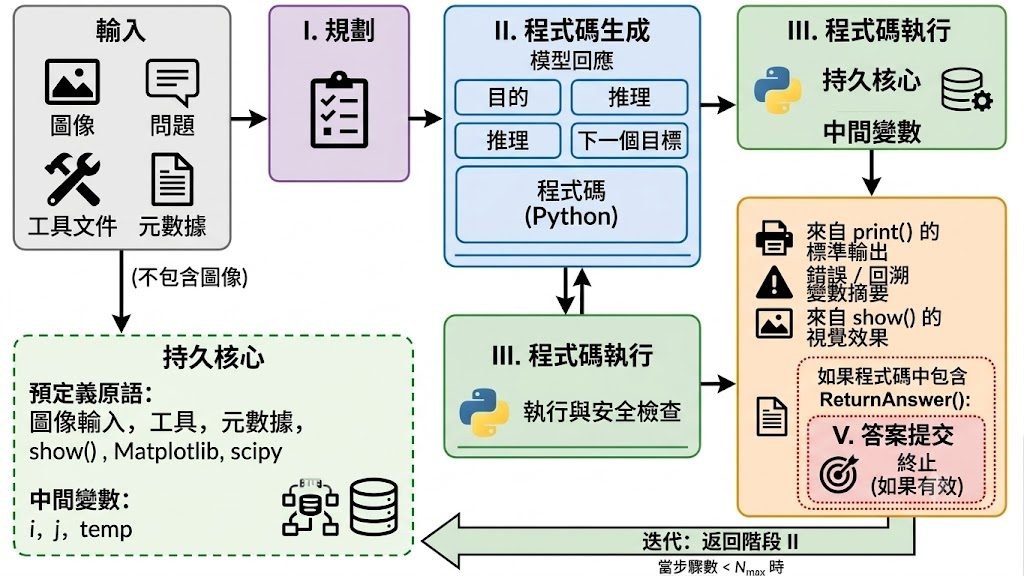
VISTA 是一個面向 GUI grounding 的訓練框架,核心目標是令模型更準確地在螢幕截圖中找出應該點擊的位置。它處理的不是一般文字理解,而是讓模型根據指令,在複雜介面上輸出座標,減少按錯按鈕、點錯輸入框這類問題。
這個項目的重點,在於它不是只從同一張截圖反覆抽樣,而是把同一個 GUI 畫面裁成多個仍保留目標元素的 view,再用這些 view 建立 GRPO 比較組。由於每個 crop 都會精確重映射座標,模型等於在語意相同、幾何位置不同的畫面上學習,能改善單一視角下「全部答錯」或「全部答中」而缺乏學習訊號的情況。
另一個關鍵設計是 self-verified cross-view anchor。它只會在目前 policy 已經產生 maximum-reward rollout 時,才加入 oracle coordinate,避免把訓練直接變成無條件模仿;這點對 GUI 座標生成尤其重要,因為短座標輸出很容易受微小偏差影響。從描述來看,這種做法比標準 GRPO 更重視穩定性,也更保留 reinforcement learning 的比較學習特性。
- 這是一個訓練方法項目,不是最終應用程式,主要用來提升 GUI grounding 模型表現
- 核心改動包括 view-consistent GRPO groups 與 self-verified cross-view anchor
- 在 ScreenSpot-Pro 上,Qwen3-VL 4B/8B/30B-A3B 由 55.5/52.7/53.7 提升至 63.4/65.8/67.0
- 以 Qwen3.5 初始化的 4B/9B/35B-A3B backbone,亦比 standard GRPO 再高 +2.0/+0.9/+1.2
- 已公開相關模型包括 VISTA-4B、VISTA-9B
如果你本身有做 Computer-use agents(CUAs)、GUI 自動化、螢幕操作代理,這個項目特別值得留意。它較適合研究人員、模型工程師,或者正在調整 Qwen3-VL、Qwen3.5 視覺語言 backbone 的團隊;一般用家未必會直接部署這個項目,但可以把它視為提升介面定位能力的一套訓練方案。
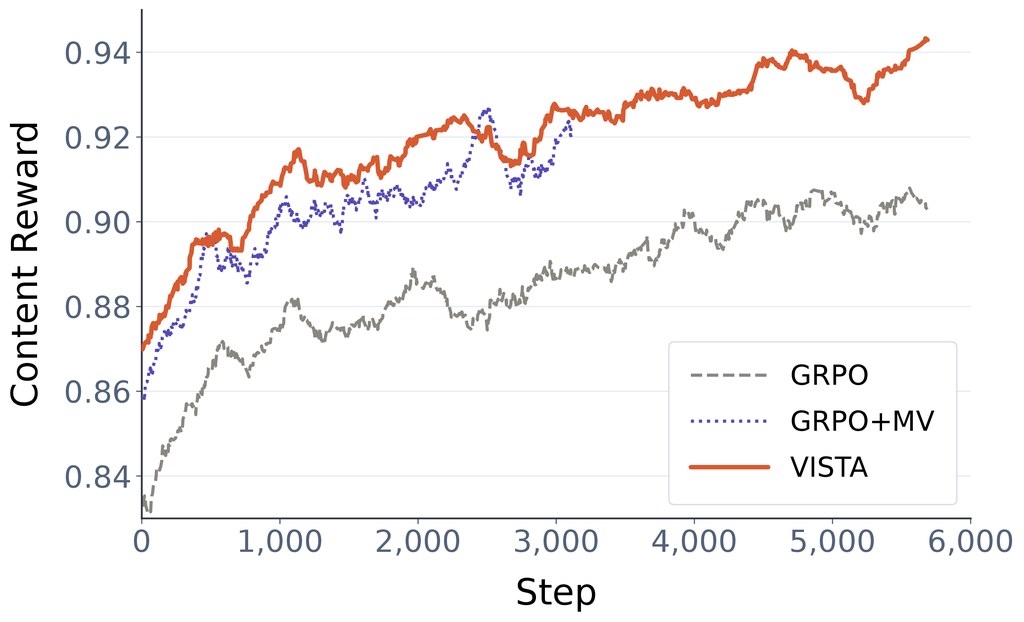
就公開資料看,VISTA 的說服力主要來自基準分數與訓練動態變化:content reward、更高的 informative group ratio,以及 ScreenSpot-Pro 準確度同步上升。再加上論文提到五個 GUI-grounding benchmarks、較高 worst-view accuracy 和較低 prediction flip rates,整體判斷是:這個項目不是靠包裝取勝,而是針對 GUI grounding 訓練訊號退化問題,提出了相當對症的改法。
GitHub: https://github.com/ZJUSCL/VISTA