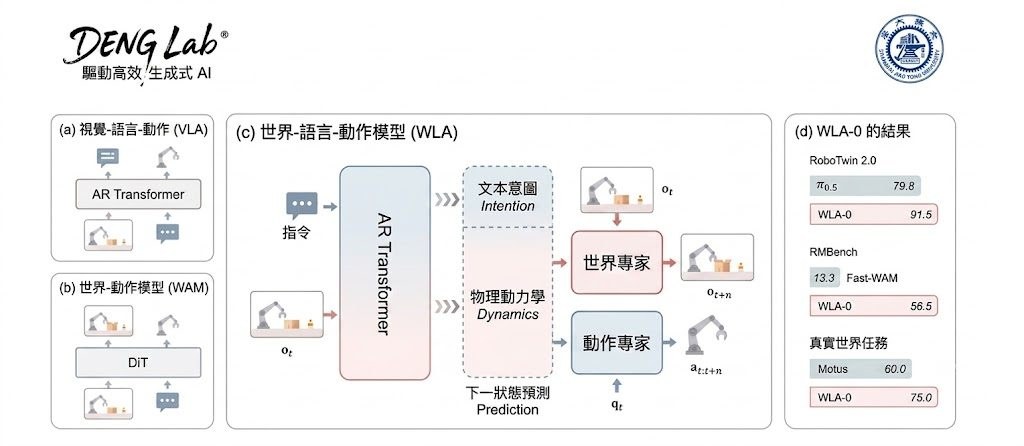
LoomVideo 由北京大學與阿里巴巴聯合發布,主打「統一多模態輸入的影片生成與編輯」,把文字、影片、圖片等多種輸入整合到同一個模型。傳統的統一影片模型動輒超過 13B 參數,且為了加入來源影片條件,往往要把所有 token 接在一起,導致序列長度翻倍、self-attention 成本暴增四倍。LoomVideo 的核心定位,就是用更小、更快的設計,達到同等甚至更好的效果。
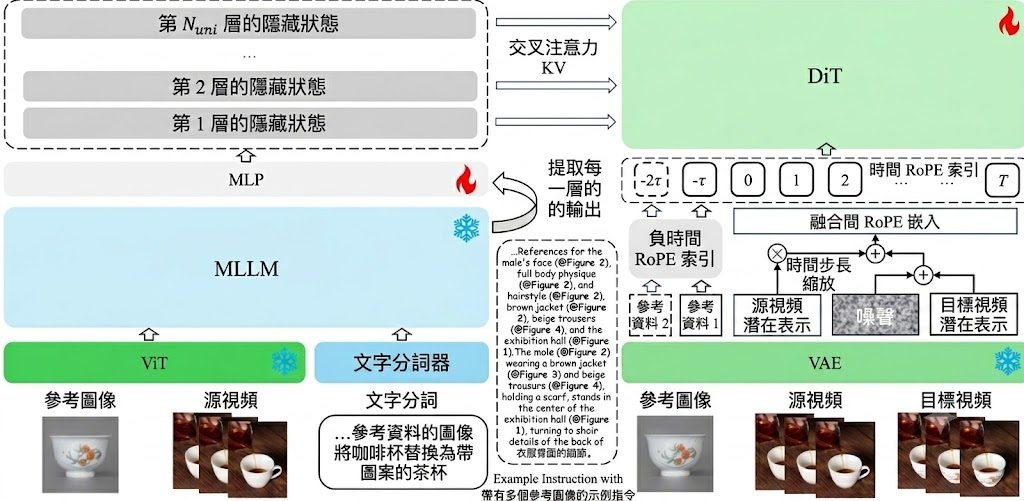
這個項目基於 MLLM(多模態大語言模型)加 DiT(Diffusion Transformer)的組合,並提出三個關鍵設計:Deepstack Injection 從 MLLM 每一層抽取特徵,再透過 cross-attention 注入對應的 DiT 層;Scale-and-Add Conditioning 把乾淨的來源影片潛在變數按時間步長縮放後直接加到雜訊目標上,免去 token 拼接的額外負擔;Negative Temporal RoPE 為參考圖片指定負的時間索引,讓多圖片條件可以無縫整合。
LoomVideo 目前支援四種任務:文生影片、純文字指令編輯、影片加圖片加文字的指令編輯,以及多張參考圖的條件生成,全部由同一個 5B 模型處理。論文報告在多項基準上取得領先或具競爭力的表現,並宣稱比同級模型快至少 5.41 倍。對於電子商務與時尚場景的影片生成,論文也展示了針對性的優勢。
這個項目適合關注影片生成效率的研究者、影像創作工具開發者,以及需要快速生成短影片內容的團隊。目前模型權重已公開在 Hugging Face 的 MSALab/LoomVideo,程式碼亦同步釋出,有興趣的讀者可以直接到 GitHub 與 Hugging Face 取得資源並測試。
重點摘要:
- 5B 參數的統一影片生成與編輯模型,定位比 13B+ 同類更輕量。
- 以 MLLM + DiT 架構為基礎,並提出 Deepstack Injection、Scale-and-Add Conditioning 與 Negative Temporal RoPE 三大設計。
- 支援文生影片、文字指令編輯、影片加圖片文字編輯,以及多圖片條件生成四種任務。
- 論文聲稱比同級模型快至少 5.41 倍,並在電商與時尚場景表現突出。
- 模型與程式碼已公開,方便研究者與開發者快速試用與改進。
GitHub: https://github.com/MSALab-PKU/LoomVideo
項目: https://msalab-pku.github.io/projects/LoomVideo/index.html